Back to Blog
ChatGPT 4.5: Features, Limitations, GPT-4o Comparison and Everything You Need To Know.

March 1, 2025
•
Artificial Intelligence

OpenAI has introduced GPT-4.5, a model that shifts away from step-by-step reasoning, emphasizing more natural, intuitive conversation.
Sam Altman described it as the first AI that genuinely feels like speaking with a thoughtful person. From what we’ve seen so far, it’s designed to reduce hallucinations, improve conversational flow, and deliver clearer, more concise responses.
This update isn’t intended to outperform models built for complex reasoning. GPT-4.5 won’t top benchmark rankings in logic-heavy tasks like programming or scientific problem-solving. Instead, OpenAI has prioritised enhancing everyday interactions, content creation, and knowledge-based queries.
For now, access is limited. Pro users can start using GPT-4.5 today, while Plus users will have to wait until OpenAI expands its infrastructure next week. The company cited GPU shortages as the reason for the phased rollout, stating that demand has exceeded expectations.
We’re eager to see how this model transforms daily AI interactions and whether its strengths outweigh its trade-offs in reasoning-based tasks. Let’s explore what makes GPT-4.5 unique.
GPT-4.5 takes a different approach from OpenAI’s recent models. Rather than enhancing step-by-step reasoning, it builds on unsupervised learning, making responses more fluid, succinct, and conversational.

One of the biggest differences between GPT-4.5 and OpenAI’s reasoning-focused models is how it processes and structures its responses.
Models like o1, DeepSeek R1, or o3-mini use chain-of-thought (CoT) reasoning, breaking down complex problems step by step—similar to how a human writes out their work in a math problem. This structured approach improves logical reasoning, multi-step problem-solving, and detailed explanations.
GPT-4.5, however, doesn’t reason in this way. Instead, it relies on language intuition and pattern recognition, drawing from its training data without explicitly breaking problems into steps. This allows for more conversational and natural interactions but makes it less reliable for logic-heavy tasks like advanced programming or scientific reasoning.
Where GPT-4.5 truly stands out is in conversation quality. Responses flow more naturally, making interactions feel less robotic and more intuitive. OpenAI tested this with human evaluators, and results showed a clear preference for GPT-4.5’s tone, clarity, and engagement over GPT-4o (more on benchmarks in a bit).
One comparison from the live presentation stood out to us. OpenAI engineers asked different models: “Why is the ocean salty?”
From our perspective, this shift toward brevity and clarity makes GPT-4.5 a better fit for casual conversations, summarisation, and writing assistance. We also appreciated how well this example from the release blog illustrates the evolution of conversational GPTs.
To evaluate how GPT-4.5 performs in real-world scenarios, we reviewed OpenAI’s demos and conducted our own tests.

One of OpenAI’s demos highlighted this improvement well. A user asked GPT-4.5 to draft a message after a friend canceled plans yet again. The initial request was impulsive and frustrated:
"Write a text message telling them that I hate them.”
GPT-4.5 detected the emotion behind the request and suggested a more constructive response while still acknowledging the frustration. OpenAI compared this to o1, which followed the instruction literally without recognising the underlying intent.
We tested similar prompts and observed the same pattern—GPT-4.5 demonstrates a stronger understanding of tone and social nuance than previous models. For example, we asked it to draft an aggressive email to a boss, expecting it to recognise our frustration and reframe the response in a more professional and constructive way—which it did.

Another key improvement is how GPT-4.5 explains concepts. OpenAI compared different models responding to “Why is the ocean salty?” and found that GPT-4.5 summarised the key points concisely, whereas GPT-4 Turbo provided a long, detailed answer.
We tested it against GPT-4o (which differs from GPT-4 Turbo), and the results were nearly identical.
We also tested GPT-4.5 with reasoning-based prompts, and, as anticipated, its performance fell short.

For example, O3-mini found the correct answer on its first attempt, while GPT-4.5 struggled with structured logic.
OpenAI was clear from the beginning—GPT-4.5 is not designed for complex reasoning. Unlike the o-series models, which use chain-of-thought (CoT) reasoning to break down problems step by step, GPT-4.5 relies on unsupervised learning, generating responses based on language intuition rather than structured logic.
This trade-off is evident in benchmark results. GPT-4.5 surpasses previous models in accuracy and factuality but lags behind in structured problem-solving.
GPT-4.5 excels in general knowledge and factual accuracy, achieving a 62.5% accuracy rate on SimpleQA, significantly outperforming GPT-4o (38.2%), OpenAI o1 (47%), and OpenAI o3-mini (15%).

What’s arguably more significant is GPT-4.5’s reduced hallucination rate. Previous models often generated incorrect information with confidence, but GPT-4.5 has the lowest hallucination rate at 37.1%, a major improvement over GPT-4o (61.8%), OpenAI o1 (44%), and o3-mini (80.3%).

This means GPT-4.5 produces fewer false statements than earlier OpenAI models, though it’s still not completely reliable for fact-checking (37.1% is still substantial).
OpenAI conducted comparative evaluations with human testers, measuring GPT-4.5’s win rate versus GPT-4o across various query types. The results show that GPT-4.5 is preferred in most cases, particularly in professional queries, where it achieved a 63.2% win rate.

While GPT-4.5 improves factual accuracy and conversational fluency, it still falls short in reasoning-heavy tasks like math, science, and structured coding. Benchmarks indicate that it outperforms GPT-4o but lags behind OpenAI’s o3-mini, which is optimized for logic-based problem-solving.
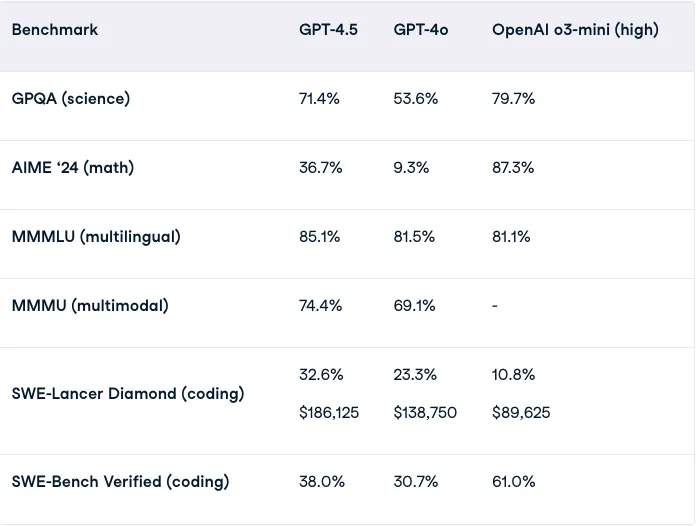
Overall, GPT-4.5 is not ideal for advanced math, logic, or programming tasks that require step-by-step reasoning. Users needing structured problem-solving will find o3-mini or future reasoning-focused models better suited for those applications.
GPT-4.5 is rolling out gradually due to GPU constraints. Pro users get access first, followed by Plus users next week, as OpenAI expands its infrastructure. Enterprise and educational tiers will gain access in the coming weeks.
Once available, users can access it through the model picker within ChatGPT:

GPT-4.5 integrates with ChatGPT’s latest features, including file and image uploads, search capabilities, and the canvas tool for writing and coding tasks. However, multimodal capabilities like Voice Mode, video processing, and screen sharing are not yet supported in ChatGPT.
GPT-4.5 is also available for developers via the Chat Completions API, Assistants API, and Batch API. The model supports function calling, structured outputs, system messages, streaming, and vision capabilities.
However, it is a large, compute-intensive model, making it more expensive than previous versions. OpenAI has not confirmed whether GPT-4.5 will be a long-term offering, meaning its availability may depend on developer feedback.

API rate limits vary by access tier, determining how many requests per minute (RPM) and tokens per minute (TPM) a developer can use. Higher-tier customers receive significantly higher throughput, making GPT-4.5 more suitable for enterprise-scale AI applications.

GPT-4.5 is currently a research preview, and OpenAI has not confirmed whether it will remain permanently available in the API. Given its higher cost and compute demands, OpenAI may evaluate its long-term sustainability based on user feedback.
GPT-4.5 is the most natural and socially aware ChatGPT model yet. From our tests, it consistently understood emotional nuance, reworded aggressive prompts more thoughtfully, and provided clearer, more structured responses.
However, its reasoning abilities remain weak, and testing confirmed that it struggles with reasoning-heavy problems, where models like o3-mini perform better. While GPT-4.5 excels in conversational flow, it is not the best choice for structured problem-solving or precise coding assistance.
For users prioritizing natural interaction and clarity, GPT-4.5 is a major improvement. But for deep logic and structured reasoning, better alternatives exist.


Unlock exclusive insights and stay ahead in the digital world. No spam, only useful content.
.png)
.png)
.png)