Back to Blog
OpenAI's Deep Research: A Comprehensive Guide with Real-World Examples

March 5, 2025
•
Learning
.webp)
OpenAI has introduced Deep Research, an advanced AI agent powered by the upcoming O3 model. This cutting-edge tool is designed to browse the web, analyze multiple sources, and synthesize large volumes of information, making it a game-changer for deep-dive investigations.
You might be wondering: Doesn’t ChatGPT already do this?
Unlike a standard ChatGPT session, which provides quick, conversational responses, Deep Research is built for multi-step investigations. It references multiple sources, compiles structured reports, and presents data-driven insights—making it ideal for tasks that require thorough research.
For example, if you've ever compared cars, software, or financial investments, you know that reliable information is scattered across different sources and takes time to gather. Deep Research automates this process, streamlining information retrieval and synthesis.
At Digital Bricks, we tested Deep Research extensively—and while its capabilities are impressive, there are also challenges, including factual inaccuracies and inference errors. In this blog, we’ll break down everything you need to know about Deep Research, explore its strengths and limitations, and share practical examples and expert prompting tips to help you maximize its potential.
OpenAI’s Deep Research is an AI-powered agent designed to conduct in-depth, multi-step research on the Internet. Unlike standard ChatGPT browsing capabilities, which provide quick responses, Deep Research autonomously finds, analyzes, and synthesizes information from hundreds of online sources.

Deep Research is designed for professionals and organizations that require comprehensive, data-driven research with accurate, well-cited insights. It is particularly valuable for:
For any task that involves browsing multiple sources, verifying data, and synthesizing structured insights, Deep Research provides a faster, more efficient, and AI-powered research solution that eliminates the need for manual searching and cross-referencing.
Deep Research is powered by an advanced version of OpenAI’s upcoming O3 model, leveraging the latest innovations in AI reasoning and web-based data analysis. Unlike standard AI models that generate responses based on pre-trained knowledge, Deep Research is specifically optimized for real-time information retrieval, multi-source verification, and structured reporting.
To achieve this, OpenAI trained Deep Research using reinforcement learning on real-world browsing and analytical tasks. This enables the model to follow a multi-step, iterative research process, allowing it to extract, evaluate, and synthesize complex topics with greater accuracy. The result is highly structured, well-cited reports that provide reliable insights for professionals, businesses, and researchers.
A key benchmark for assessing AI-driven research models is Humanity’s Last Exam, a newly developed test designed to measure AI performance on expert-level multiple-choice and short-answer questions across 100+ disciplines, including linguistics, rocket science, ecology, and mathematics.
This benchmark evaluates an AI’s ability to reason across multiple fields, seek out specialized knowledge, and synthesize insights from authoritative sources—all of which are critical for AI-powered research applications.
Deep Research set a new accuracy record of 26.6%, significantly outperforming previous AI models:
The most notable improvements were observed in chemistry, humanities, social sciences, and mathematics, where Deep Research demonstrated an advanced ability to analyze complex problems, retrieve relevant information, and generate well-structured reports.
This leap in performance highlights Deep Research’s potential as a powerful AI tool for real-time, multi-source analysis, making it an essential solution for organizations that rely on data-driven decision-making, academic research, and industry intelligence.

GAIA (General AI Agent benchmark) is designed to assess how well AI systems handle real-world, complex queries by testing their ability to integrate reasoning, web browsing, multimodal fluency, and tool-use proficiency. This benchmark measures an AI model’s ability to retrieve, analyze, and synthesize information from multiple sources, making it a critical evaluation for research-oriented AI agents.
Deep Research set a new state-of-the-art (SOTA) record, securing the top position on the external GAIA leaderboard with strong performance across all levels of complexity. It demonstrated particularly high accuracy in Level 3 tasks, which involve multi-step reasoning, deep research, and synthesis of complex information from diverse sources.

Deep Research’s high pass@1 score indicates that its initial attempt at answering a GAIA question is more accurate than previous models, reducing the need for repeated refinements. Additionally, its cons@64 score, which measures performance across multiple response attempts, highlights its ability to self-correct and refine answers by incorporating new information.
By excelling in multi-step research, data validation, and structured synthesis, Deep Research showcases its potential as a highly reliable AI tool for professionals, businesses, and researchers who require fact-based, real-time insights.
In addition to external benchmarks, OpenAI conducted internal evaluations to assess Deep Research’s capabilities on expert-level tasks. These assessments were carried out by domain experts, providing deeper insights into the model’s ability to handle complex, multi-step research queries.
One of the most revealing findings from these evaluations is how Deep Research’s accuracy improves as it makes more tool calls. The model’s pass rate increases when it is allowed to browse, retrieve, and analyze data iteratively, demonstrating the importance of giving the AI time to refine its research process.
This iterative browsing ability sets Deep Research apart from traditional AI models, as it can continuously fact-check, refine its findings, and improve the accuracy of its responses—a crucial capability for businesses and professionals who rely on AI-driven research for decision-making.

Let’s take a look at another graph—see below. Deep Research performs best on tasks with lower estimated economic value, with accuracy dropping as the task’s potential financial impact increases. This suggests that more economically significant tasks tend to be more complex or rely on proprietary knowledge that isn’t widely accessible online.
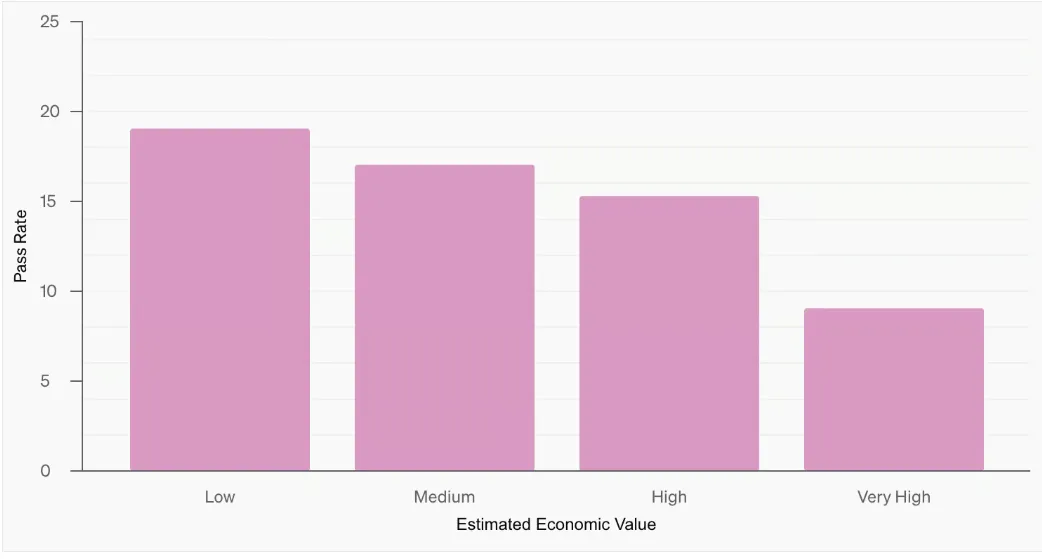
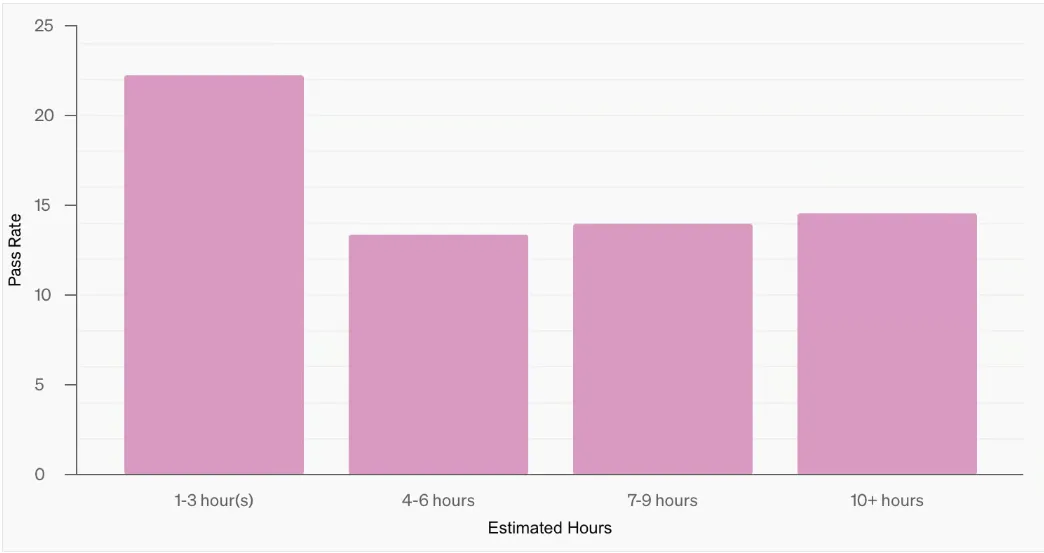
A key insight from OpenAI’s internal evaluations is how Deep Research’s accuracy compares to human effort. The analysis contrasts pass rates with the estimated time a human would need to complete each research task.
The model performs most effectively on tasks that would take a human 1-3 hours, demonstrating its ability to efficiently handle moderately complex research inquiries. However, performance does not decline in a linear fashion as task duration increases, suggesting that AI struggles with different types of complexity than humans do. This indicates that while AI excels in structured, data-driven research, certain nuanced or highly specialized tasks may still require human expertise to complement AI’s capabilities. Understanding these strengths and limitations is key to optimizing AI-human collaboration in research workflows.
At the time of publishing, Deep Research is only available to Pro users, with a limit of 100 queries per month. However, OpenAI has announced plans to expand access to Plus, Team, and Enterprise users soon.
Deep Research is still in an early phase, showing both promise and limitations. The first example below highlights some of its challenges, while the second demonstrates its potential for transforming AI-assisted research.
One of the biggest challenges I face is getting a complete and up-to-date overview of the AI ecosystems of different companies. Take Google, for example—they have Gemini 2.0 Flash, Imagen 3, Veo 2, Project Mariner, and Project Astra. But what else am I missing? To finally get a comprehensive summary, I prompted Deep Research with this request.

Before beginning the research, the model asked for clarifications. In all my tests, regardless of how detailed my initial prompt was, Deep Research always attempted to refine the query before proceeding. This was helpful, as I often assumed my prompts were clear when, in reality, they benefited from additional refinement.
Once I answered its clarifications, Deep Research initiated the search, displaying its sources and browsing activity in real-time on the right side of the browser. The process took 11 minutes and involved consulting 25 sources. Since a single source refers to a parent website, and the model browses multiple pages per source, this means the system likely analyzed around 100 web pages.

Even though I didn’t specify a structure, the response was well-organized, with proper use of headings, bold text, bullet points, and clear sections.
The sources were cited immediately after each claim, making it easy to fact-check the information.
The report provided a solid balance of detail and length—concise but not superficial. If I needed additional depth, I could simply request more details.
These issues make trusting Deep Research difficult. In this case, I tested it on a subject I’m highly familiar with, so I could fact-check the response. But what if I had relied on Deep Research for a topic I knew nothing about?
Since Deep Research struggled with identifying the most up-to-date information, I decided to test it on a more evergreen topic—one that doesn’t rely heavily on recent developments.
I drive a 2013-model car and occasionally consider replacing it. However, I always get stuck on the same question: should I buy a new or used vehicle? New cars depreciate quickly, but older ones may come with higher repair costs. I wanted to know what experts think, so I asked Deep Research to compile a report based on industry studies, market data, and consumer opinions.
Before running the query, I used a quick prompt optimization tip:
I first tested my query in a separate LLM, instructing it with:
"You are a prompt engineer. Help me refine this prompt: (insert prompt here)."
This process helped optimize my instructions for Deep Research, ensuring greater clarity and precision.

Once again, Deep Research asked for clarifications before starting the task. The entire research session took six minutes and involved browsing multiple pages across 12 sources. You can read the full report here.
The breadth of insights was far beyond what I expected. Deep Research analyzed academic studies, industry reports, market trends, insurance cost comparisons, and depreciation data—offering perspectives I had never considered before.
By my estimate, Deep Research saved me more than 10 hours of manual browsing and research.
Since I’m not an expert in this field, I can’t fully verify the accuracy of every claim, but from a consumer’s perspective, the insights were logical and well-structured. I fact-checked a few key points against the cited sources and found no inconsistencies.
Like in the first example, the response was well-structured and balanced in depth. One of my favorite parts was the table comparing depreciation values, which clearly illustrated why holding onto my 12-year-old hybrid might be the smarter financial decision.

OpenAI’s Deep Research has the potential to save users significant time by automating multi-source research and analysis. However, its limitations in retrieving up-to-date information and occasional inaccuracies mean that users must approach its outputs with caution.
While OpenAI has acknowledged that Deep Research is still in its early phase, its performance on evergreen topics suggests strong potential for AI-powered research tools.
Despite its flaws, we will continue testing Deep Research, and Digital Bricks looks forward to seeing how OpenAI refines and enhances its capabilities over time.


Unlock exclusive insights and stay ahead in the digital world. No spam, only useful content.
.webp)
.webp)
.webp)